In this previous post, I describe a relatively simple version of an expected goals model that I’ve been developing recently. In this post, I want to examine the limitations and uncertainties relating to how well the model predicts goals.
Just to recap, I built the model using data from the Premier League from 2013/14 and 2014/15. For the analysis below, I’m just going to focus on non-penalty shots with the foot, so it includes both open-play and set piece shot situations. Mixing these will introduce some bias but we have to start somewhere. The data amounts to over 16,000 shots.
What follows is a long and technical post. You have been warned.
Putting the boot in
One thing to be aware of is how the model might differ if we used a different set of shots for input; ideally the answer we get shouldn’t change if we only used a subset of the data or if we resample the data. If the answer doesn’t change appreciably, then we can have more confidence that the results are robust.
Below, I’ve used a statistical technique known as ‘bootstrapping‘ to assess how robust the regression is for expected goals. Bootstrapping belongs to a class of statistical methods known as resampling. The method works by randomly extracting shots from the dataset and rerunning the regression many times (1000 times in the plot below). Using this, I can estimate a confidence interval for my expected goal model, which should provide a reasonable estimate of goal expectation for a given shot.
For example, the base model suggests that a shot from the penalty spot has an xG value of 0.19. The bootstrapping suggests that the 90% confidence interval gives an xG range from 0.17 to 0.22. What this means is that on 90% of occasions that Premier League footballers take a shot from the penalty spot, we would expect them to score somewhere between 17-22% of the time.
The plot below shows the goal expectation for a shot taken in the centre of the pitch at varying distances from the goal. Generally speaking, the confidence interval range is around ±1-2%. I also ran the regressions on subsets of the data and found that after around 5000 shots, the central estimate stabilised and the addition of further shots in the regression just narrows the confidence intervals. After about 10,000 shots, the results don’t change too much.

Expected goal curve for shots in the centre of the pitch at varying distances from the goal. Shots with the foot only. The red line is the median expectation, while the blue shaded region denotes the 90% confidence interval.
I can use the above information to construct a confidence interval for the expected goal totals for each team, which is what I have done below. Each point represents a team in each season and I’ve compared their expected goals vs their actual goals. The error bars show the range for the 90% confidence intervals.
Most teams line up with the one-to-one line within their respective confidence intervals when comparing with goals for and against. As I noted in the previous post, the overall tendency is for actual goals to exceed expected goals at the team level.

Expected goals vs actual goals for teams in the 2013/14 and 2014/15 Premier League. Dotted line is the 1:1 line, the solid line is the line of best fit and the error bars denote the 90% confidence intervals based on the xG curve above.
As an example of what the confidence intervals represent, in the 2013/14 season, Manchester City’s expected goal total was 59.8, with a confidence interval ranging from 52.2 to 67.7 expected goals. In reality, they scored 81 non-penalty goals with their feet, which falls outside of their confidence interval here. On the plot below, Manchester City are the red marker on the far right of the expected goals for vs actual goals for plot.
Embracing uncertainty
Another method of testing the model is to look at the model residuals, which are calculated by subtracting the outcome of a shot (either zero or one) from its expected goal value. If you were an omnipotent being who knew every aspect relating to the taking of a shot, you could theoretically predict the outcome of a shot (goal or no goal) perfectly (plus some allowance for random variation). The residuals of such a model would always be zero as the outcome minus the expectation of a goal would equal zero in all cases. In the real world though, we can’t know everything so this isn’t the case. However, we might expect that over a sufficiently large sample, the residual will be close to zero.
In the figure below, I’ve again bootstrapped the data and looked at the model residuals as the number of shots increases. I’ve done this 10,000 times for each number of shots i.e. I extract a random sample from the data and then calculate the residual for that number of shots. The red line is the median residual (goals minus expected goals), while the blue shaded region corresponds to the standard error range (calculated as the 90% confidence interval). The residual is normalised to a per shot basis, so the overall uncertainty value is equal to this value multiplied by the number of shots taken.
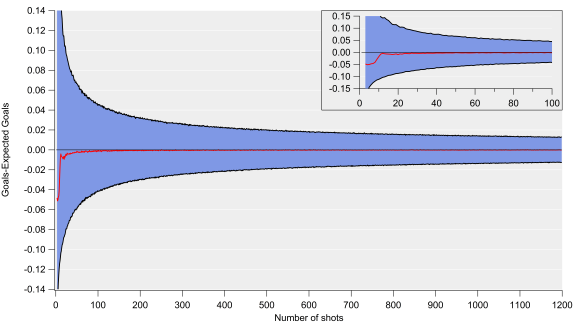
Goals-Expected Goals versus number of shots calculated via bootstrapping. Inset focusses on the first 100 shots. The red line is the median, while the blue shaded region denotes the 90% confidence interval (standard error).
The inset shows how this evolves up to 100 shots and we see that over about 10 shots, the residual approaches zero but the standard errors are very large at this point. Consequently, our best estimate of expected goals is likely highly uncertain over such a small sample. For example, if we expected to score two goals from 20 shots, the standard error range would span 0.35 to 4.2 goals. To add a further complication, the residuals aren’t normally distributed at that point, which makes interpretations even more challenging.
Clearly there is both a significant amount of variation over such small samples, which could be a consequence of both random variation and factors not included in the model. This is an important point when assessing xG estimates for single matches; while the central estimate will likely have a very small residual, the uncertainty range is huge.
As the sample size increases, the uncertainty decreases. After 100 shots, which would equate to a high shot volume for a forward, the uncertainty in goal expectation would amount to approximately ±4 goals. After 400 shots, which is close to the average number of shots a team would take over a single season, the uncertainty would equate to approximately ±9 goals. For a 10% conversion rate, our expected goal value after 100 shots would be 10±4, while after 400 shots, our estimate would be 40±9 (note the percentage uncertainty decreases as the number of shots increases).
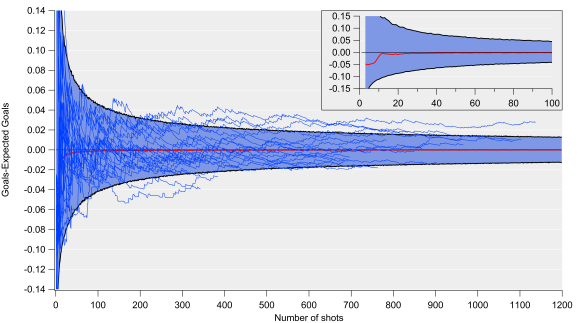
Same as above but with individual teams overlaid.
Above is the same plot but with the residuals shown for each team over the past two seasons (or one season if they only played for a single season). The majority of teams fall within the uncertainty envelope but there are some notable deviations. At the bottom of the plot are Burnley and Norwich, who significantly under-performed their expected goal estimate (they were also both relegated). On the flip side, Manchester City have seemingly consistently outperformed the expected goal estimate. Part of this is a result of the simplicity of the model; if I include additional factors such as how the chance is created, the residuals are smaller.
How well does an xG model predict goals?
Broadly speaking, the central estimates of expected goals appear to be reasonably good; the residuals tend to zero quickly and even though there is some bias, the correlations and errors are encouraging. When the uncertainties in the model are propagated through to the team level, the confidence intervals are on average around ±15% for expected goals for and against.
When we examine the model errors in more detail, they tend to be larger (around ±25% at the team level over a single season). The upshot of all this is that there appears to be a large degree of uncertainty in expected goal values when considering sample sizes relevant at the team and player level. While the simplicity of the model used here may mean that the uncertainty values shown represent a worst-case scenario, it is still something that should be considered when analysts make statements and projections. Having said this, based on some initial tests, adding extra complexity doesn’t appear to reduce the residuals to any great degree.
Uncertainty estimates and confidence intervals aren’t sexy and having spent the last 1500ish words writing about them, I’m well aware they aren’t that accessible either. However, I do think they are useful and important in the real world.
Quantifying these uncertainties can help to provide more honest assessments and recommendations. For example, I would say it is more useful to say that my projections estimate that player X will score 0.6-1.4 goals per 90 minutes next season along with some central value, rather than going with a single value of 1 goal per 90 minutes. Furthermore, it is better to state such caveats in advance – if you just provided the central estimate and the player posted say 0.65 goals per 90 and you then bring up your model’s uncertainty range, you will just sound like you’re making excuses.
This also has implications regarding over and under performance by players and teams relative to expected goals. I frequently see statements about regression to the mean without considering model errors. As George Box wisely noted:
Statisticians, like artists, have the bad habit of falling in love with their models.
This isn’t to say that expected goal models aren’t useful, just that if you want to wade into the world of probability and modelling, you should also illustrate the limitations and uncertainties associated with the analysis.
Perhaps those using expected goal models are well aware of these issues but I don’t see much discussion of it in public. Analytics is increasingly finding a wider public audience, along with being used within clubs. That will often mean that those consuming the results will not be aware of these uncertainties unless you explain them. Speaking as a researcher who is interested in the communication of science, I can give many examples of where not discussing uncertainty upfront can backfire in the long run.
Isn’t uncertainty fun!
——————————————————————————————————————–
Thanks to several people who were kind enough to read an initial draft of this article and the proceeding method piece.
Like this:
Like Loading...

