One of the charges against analytics is that it hasn’t really demonstrated its utility, particularly in relation to recruitment. This is an argument I have some sympathy with. Having followed football analytics for over three years, I’m well-versed in the metrics that could aid decision making in football but I can appreciate that the body of work isn’t readily accessible without investing a lot of time.
Furthermore, clubs are understandably reticent about sharing the methods and processes that they follow, so successes and failures attributable to analytics are difficult to unpick from the outside.
Rather than add to the pile of analytics in football think-pieces that have sprung up recently, I thought I would try and work through how analysing and interpreting data might work in practice from the point of view of recruitment. Show, rather than tell.
While I haven’t directly worked with football clubs, I have spoken with several people who do use numbers to aid recruitment decisions within them, so I have some idea of how the process works. Data analysis is a huge part of my job as a research scientist, so I have a pretty good understanding of the utility and limits of data (my office doesn’t have air-conditioning though and I rarely use spreadsheets).
As a broad rule of thumb, public analytics (and possibly work done in private also) is generally ‘better’ at assessing attacking players, with central defenders and goalkeepers being a particular blind-spot currently. With that in mind, I’m going to focus on two attacking midfielders that Liverpool signed over the past two summers, Adam Lallana and Roberto Firmino.
The following is how I might employ some analytical tools to aid recruitment.
Initial analysis
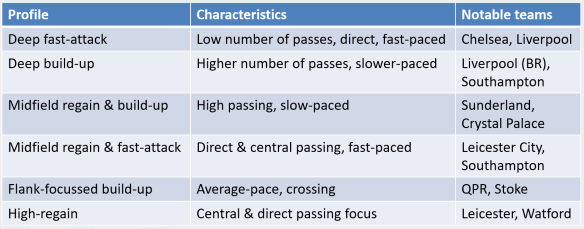
To start with I’m going to take a broad look at their skill sets and playing style using the tools that I developed for my OptaPro Forum presentation, which can be watched here. The method uses a variety of metrics to identify different player types, which can give a quick overview of playing style and skill set. The midfielder groups isolated by the analysis are shown below.

Midfield sub-groups identified using the playing style tool. Each coloured circle corresponds to an individual player. Data via Opta.
I think this is a useful starting point for data analysis as it can give a quick snap shot of a player and can also be used for filtering transfer requirements. The utility of such a tool is likely dependent on how well scouted a particular league is by an individual club.
A manager, sporting director or scout could feed into the use of such a tool by providing their requirements for a new signing, which an analyst could then use to provide a short-list of different players. I know that this is one way numbers are used within clubs as the number of leagues and matches that they take an interest in outstrips the number of ‘traditional’ scouts that they employ.
As far as our examples are concerned, Lallana profiles as an attacking midfielder (no great shock) and Firmino belongs in the ‘direct’ attackers class as a result of his dribbling and shooting style (again no great shock). Broadly speaking, both players would be seen as attacking midfielders but the analysis is picking up their differing styles which are evident from watching them play.
Comparing statistical profiles
Going one step further, fairer comparisons between players can be made based upon their identified style e.g. marking down a creative midfielders for taking a low number of shots compared to a direct attacker would be unfair, given their respective roles and playing style.
Below I’ve compared their statistical output during the 2013/14 season, which is the season before Lallana signed for Liverpool and I’m going to make the possibly incorrect assumption that Firmino was someone that Liverpool were interested in that summer also. Some of the numbers (shots, chances created, throughballs, dribbles, tackles and interceptions) were included in the initial player style analysis above, while others (pass completion percentage and assists) are included as some additional context and information.
The aim here is to give an idea of the strengths, weaknesses and playing style of each player based on ranking a player against their peers. Whether a player ranks low or high on a particular metric is a ‘good’ thing or not is dependent on the statistic e.g. taking shots from outside the box isn’t necessarily a bad thing to do but you might not want to be top of the list (Andros Townsend in case you hadn’t guessed). Many will also depend on the tactical system of their team and their role within it.
The plots below are to varying degrees inspired by Ted Knutson, Steve Fenn and Florence Nightingale (Steve wrote about his ‘gauge’ graph here). There are more details on these figures at the bottom of the post*.

Data via Opta.
Lallana profiles as a player who is good/average at several things, with chances created seemingly being his stand-out skill here (note this is from open-play only). Firmino on the other hand is strong and even elite at several of these measures. Importantly, these are metrics that have been identified as important for attacking midfielders and they can also be linked to winning football matches.

Data via Opta.
Based on these initial findings, Firmino looks like an excellent addition, while Lallana is quite underwhelming. Clearly this analysis doesn’t capture many things that are better suited to video and live scouting e.g. their defensive work off the ball, how they strike a ball, their first touch etc.
At this stage of the analysis, we’ve got a reasonable idea of their playing style and how they compare to their peers. However, we’re currently lacking further context for some of these measures, so it would be prudent to examine them further using some other techniques.
Diving deeper
So far, I’ve only considered one analytical method to evaluate these players. An important thing to remember is that all methods will have their flaws and biases, so it would be wise to consider some alternatives.
For example, I’m not massively keen on ‘chances created’ as a statistic, as I can imagine multiple ways that it could be misleading. Maybe it would be a good idea then to look at some numbers that provide more context and depth to ‘creativity’, especially as this should be a primary skill of an attacking midfielder for Liverpool.
Over the past year or so, I’ve been looking at various ways of measuring the contribution and quality of player involvement in attacking situations. The most basic of these looks at the ability of a player to find his team mates in ‘dangerous’ areas, which broadly equates to the central region of the penalty area and just outside it.
Without wishing to go into too much detail, Lallana is pretty average for an attacking midfielder on these metrics, while Firmino was one of the top players in the Bundesliga.
I’m wary of writing Lallana off here as these measures focus on ‘direct’ contributions and maybe his game is about facilitating his team mates. Perhaps he is the player who makes the pass before the assist. I can look at this also using data by looking at the attacks he is involved in. Lallana doesn’t rise up the standings here either, again the quality and level of his contribution is basically average. Unfortunately, I’ve not worked up these figures for the Bundesliga, so I can’t comment on how Firmino shapes up here (I suspect he would rate highly here also).
Recommendation
Based on the methods outlined above, I would have been strongly in favour of signing Firmino as he mixes high quality creative skills with a goal threat. Obviously it is early days for Firmino at Liverpool (a grand total of 239 minutes in the league so far), so assessing whether the signing has been successful or not would be premature.
Lallana’s statistical profile is rather average, so factoring in his age and price tag, it would have seemed a stretch to consider him a worthwhile signing based on his 2013/14 season. Intriguingly, when comparing Lallana’s metrics from Southampton and those at Liverpool, there is relatively little difference between them; Liverpool seemingly got the player they purchased when examining his statistical output based on these measures.
These are my honest recommendations regarding these players based on these analytical methods that I’ve developed. Ideally I would have published something along these lines in the summer of 2014 but you’ll just have to take my word that I wasn’t keen on Lallana based on a prototype version of the comparison tool that I outlined above and nothing that I have worked on since has changed that view. Similarly, Firmino stood out as an exciting player who Liverpool could reasonably obtain.
There are many ways I would like to improve and validate these techniques and they might bear little relation to the tools used by clubs. Methods can always be developed, improved and even scraped!
Hopefully the above has given some insight into how analytics could be a part of the recruitment process.
Coda
If analytics is to play an increasing role in football, then it will need to build up sufficient cachet to justify its implementation. That is a perfectly normal sequence for new methods as they have to ‘prove’ themselves before seeing more widespread use. Analytics shouldn’t be framed as a magic bullet that will dramatically improve recruitment but if it is used well, then it could potentially help to minimise mistakes.
Nothing that I’ve outlined above is designed to supplant or reduce the role of traditional scouting methods. The idea is just to provide an additional and complementary perspective to aid decision making. I suspect that more often than not, analytical methods will come to similar conclusions regarding the relative merits of a player, which is fine as that can provide greater confidence in your decision making. If methods disagree, then they can be examined accordingly as a part of the process.
Evaluating players is not easy, whatever the method, so being able to weigh several assessments that all have their own strengths, flaws, biases and weaknesses seems prudent to me. The goal of analytics isn’t to create some perfect and objective representation of football; it is just another piece of the puzzle.
truth … is much too complicated to allow anything but approximations – John von Neumann
*I’ve done this by calculating percentile figures to give an indication of how a player compares with their peers. Values closer to 100 indicate that a player ranks highly in a particular statistic, while values closer to zero indicate they attempt or complete few of these actions compared to their peers. In these examples, Lallana and Firmino are compared with other players in the attacking midfielder, direct attacker and through-ball merchant groups. The white curved lines are spaced every ten percentiles to give a visual indication of how the player compares, with the solid shading in each segment corresponding to their percentile rank.
Like this:
Like Loading...

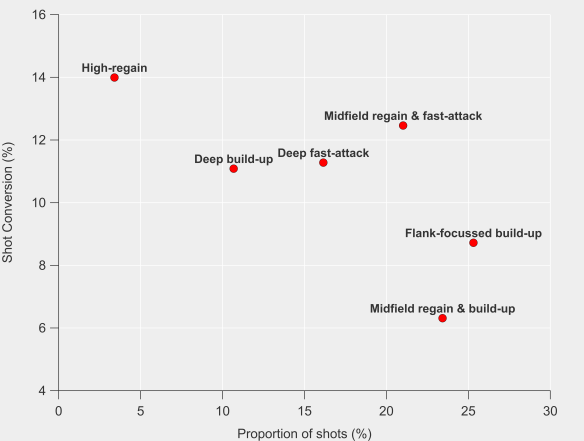
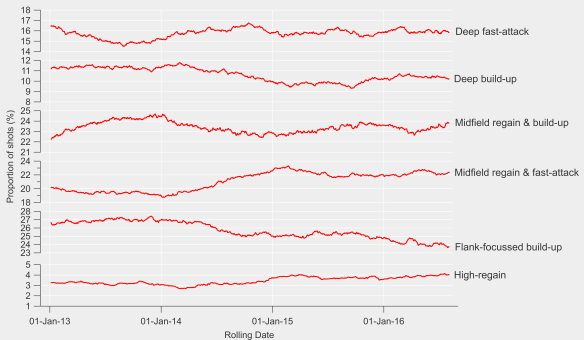




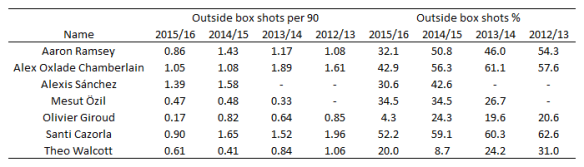 The general trend is that Arsenal’s players have been taking fewer shots from outside of the box this season compared to previous and that there has been a decline proportionally for most players also. Some of that may be driven by changing roles/positions in the team but there appears to be a clear shift in their shot profiles. Giroud for example has taken just 3 shots from outside the box this season, which is in stark contrast to his previous profile.
The general trend is that Arsenal’s players have been taking fewer shots from outside of the box this season compared to previous and that there has been a decline proportionally for most players also. Some of that may be driven by changing roles/positions in the team but there appears to be a clear shift in their shot profiles. Giroud for example has taken just 3 shots from outside the box this season, which is in stark contrast to his previous profile.